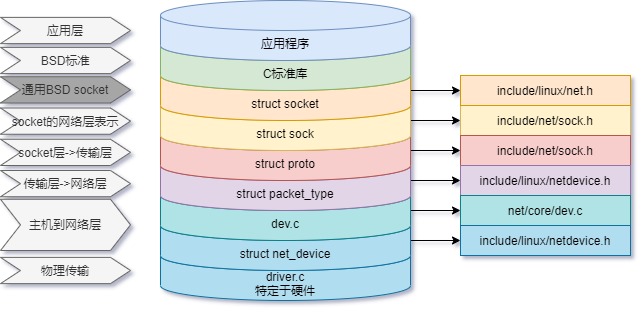
在“ 自上而下理解内核网络(一)—TCP应用层介绍”我们介绍了一个简易的TCP server和TCP client,结合上一节中对Linux kernel中网络分层的相关知识,我们这一节展示在内核应用层的相关操作:
- 用户空间
socket()之后内核空间做了什么事情? - 发送数据
- 接收数据
创建socket
不管是TCP服务端还是TCP客户端,建立的第一步都是创建socket。因此,我们这里首先展示一下,socket()之后都发生了什么?
为了方便观察,我们这里先将调用关系进行展示,然后再分析每一步的功能。调用关系如下图所示:
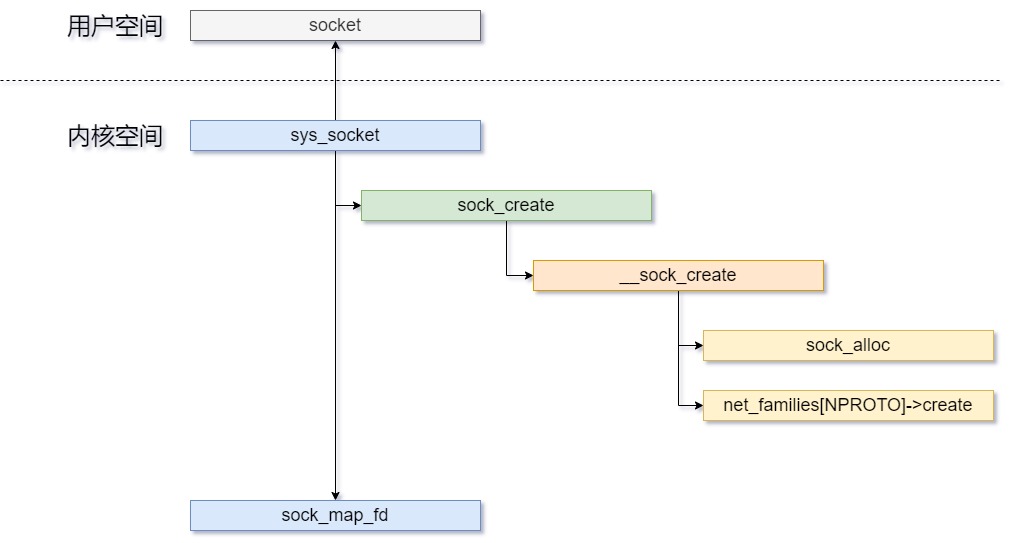
用户空间调用
socket()函数;int socket(int domain, int type, int protocol);通过
socketcall系统调用,调用sys_socket()函数,这里进入内核空间。long sys_socket(int family, int type, int protocol);在
sys_socket()中,- 这里涉及到一个宏定义BUILD_BUG_ON,意思是该宏定义后的值为真,则会导致编译出错,这里用来检查常量的一致性;
在
sys_socket()中,接着调用了sock_create(family, type, protocol, &sock)函数;int sock_create(int family, int type, int protocol, struct socket **res);该函数内部没有其他任务,直接调用了函数
__sock_create(current->nsproxy->net_ns, family, type, protocol, res, 0);int __sock_create(struct net *net, int family, int type, int protocol, struct socket **res, int kern)在
__sock_create()函数中,主要做了两件事情:申请内存和注册当前协议到全局数组net_families[NPROTO],该数组定义在net/socket.c中,声明位于include/linux/net.h文件;struct net_proto_family { int family; int (*create)(struct net *net, struct socket *sock, int protocol, int kern); struct module *owner; };申请内存调用的接口是
sock_alloc(),在这里主要有3个功能- 从全局变量
sock_mnt中获取1个inode,sock_mnt是在sock_init()过程中获得的一个大块的空间; - 通过
SOCKET_I()来间接的调用宏container_of,来通过inode,获得socket的指针;关于container_of的用法,可以参考这里。 - 同时,这里将inode和socke两个对象联合起来。
- 最后,发回
struct socket *;
// net/socket.c /** * sock_alloc - allocate a socket * * Allocate a new inode and socket object. The two are bound together * and initialised. The socket is then returned. If we are out of inodes * NULL is returned. */ static struct vfsmount *sock_mnt __read_mostly; struct socket *sock_alloc(void) { struct inode *inode; struct socket *sock; inode = new_inode_pseudo(sock_mnt->mnt_sb); if (!inode) return NULL; sock = SOCKET_I(inode); kmemcheck_annotate_bitfield(sock, type); inode->i_ino = get_next_ino(); inode->i_mode = S_IFSOCK | S_IRWXUGO; inode->i_uid = current_fsuid(); inode->i_gid = current_fsgid(); inode->i_op = &sockfs_inode_ops; this_cpu_add(sockets_in_use, 1); return sock; }- 从全局变量
到这里,
sock_create()就执行完成了,接下来执行sock_map_fd()函数。static int sock_map_fd(struct socket *sock, int flags);map_sock_fd主要用于对socket的file指针初始化,经过sock_map_fd()操作后,socket就通过其**file*指针与VFS管理的文件进行了关联,便可以进行文件的各种操作,如read、write、lseek、ioctl等.static int sock_map_fd(struct socket *sock, int flags) { struct file *newfile; int fd = get_unused_fd_flags(flags); if (unlikely(fd < 0)) return fd; newfile = sock_alloc_file(sock, flags, NULL); if (likely(!IS_ERR(newfile))) { fd_install(fd, newfile); return fd; } put_unused_fd(fd); return PTR_ERR(newfile); }至此,一个socket的创建就完成了,最终,返回到应用层的socket()就是一个socket的文件描述符。
发送数据
用户空间在发送数据时,可以调用write接口直接写入,或者使用与网络有关的接口send、sendto函数。
这些函数的控制流在内核中的某个位置会合并为一,因此,我们这里以网络有关的send和sendto接口为例,查看在应用层发送函数的控制流。
为了方便观察send&sendto,我们这里先将调用关系进行展示,然后再分析每一步的功能。调用关系如下图所示:
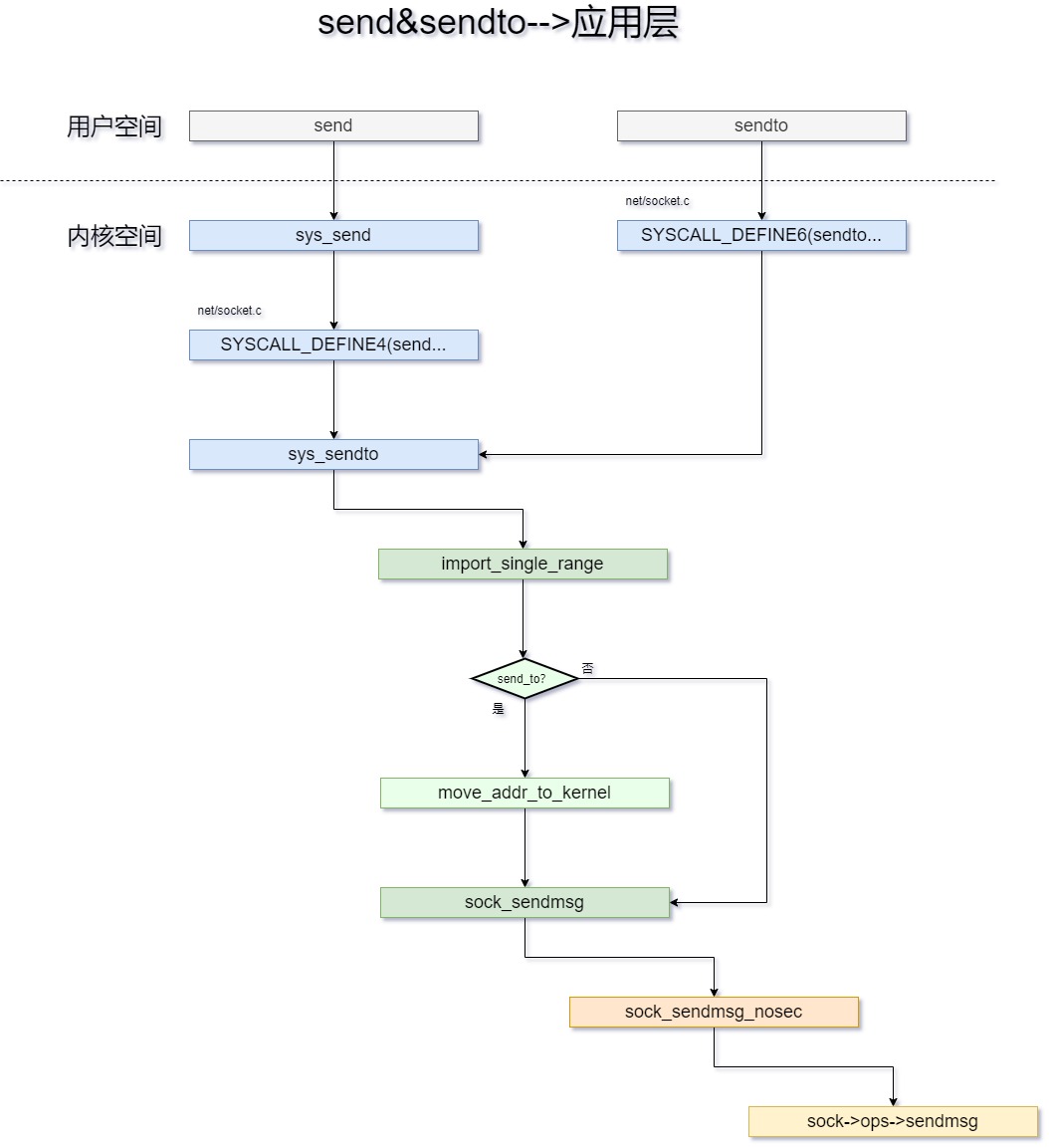
当在应用层调用send或者sendto的时候,首先会进入glibc,通过标准库的调用,会调用
sys_send()和sys_sendto();在
sys_send()的系统调用实现中,我们可以看到在调用中直接调用了sys_sendto()函数;现在,我们知道了在sys_send()和sys_sendto()函数一开始,就都进入了sys_sendto()函数的入口。
//pathname:net/socket.c /* * Send a datagram down a socket. */ SYSCALL_DEFINE4(send, int, fd, void __user *, buff, size_t, len, unsigned int, flags) { return sys_sendto(fd, buff, len, flags, NULL, 0); }我们在进入
sys_sendto()函数之前,这里展示一下send()和sendto()的函数声明,要明确的是,在send()声明中,是没有入参目的地址dest_addr;ssize_t send(int sockfd, const void *buf, size_t len, int flags); ssize_t sendto(int sockfd, const void *buf, size_t len, int flags,const struct sockaddr *dest_addr, socklen_t addrlen);现在,我们进入
sys_sendto()的函数,这里主要做了4个工作:填充要发送的内容到msg.msg_iter;
通过入参fd查找对应的socket;
组织消息。当由
sys_sendto()调用时,即addr不为空,则调用move_addr_to_kernel()将sockaddr从用户态拷贝到内核态;int move_addr_to_kernel(void __user *uaddr, int ulen, struct sockaddr_storage *kaddr);sock_sendmsg调 用 特 定 于 协 议 的 发 送 例 程sock->ops->sendmsg。该例程产生一个所需协议格式的分组,并转发到更低的协议层,这里一般就是传输层。
//pathname:net/socket.c /* * Send a datagram to a given address. We move the address into kernel * space and check the user space data area is readable before invoking * the protocol. */ SYSCALL_DEFINE6(sendto, int, fd, void __user *, buff, size_t, len, unsigned int, flags, struct sockaddr __user *, addr, int, addr_len) { struct socket *sock; struct sockaddr_storage address; int err; struct msghdr msg; struct iovec iov; int fput_needed; err = import_single_range(WRITE, buff, len, &iov, &msg.msg_iter); if (unlikely(err)) return err; sock = sockfd_lookup_light(fd, &err, &fput_needed); if (!sock) goto out; msg.msg_name = NULL; msg.msg_control = NULL; msg.msg_controllen = 0; msg.msg_namelen = 0; if (addr) { err = move_addr_to_kernel(addr, addr_len, &address); if (err < 0) goto out_put; msg.msg_name = (struct sockaddr *)&address; msg.msg_namelen = addr_len; } if (sock->file->f_flags & O_NONBLOCK) flags |= MSG_DONTWAIT; msg.msg_flags = flags; err = sock_sendmsg(sock, &msg); out_put: fput_light(sock->file, fput_needed); out: return err; }
接收数据
用户层使用recv和recvfrom函数来接收socket收到的数据,在内核应用层的接收流程如下:
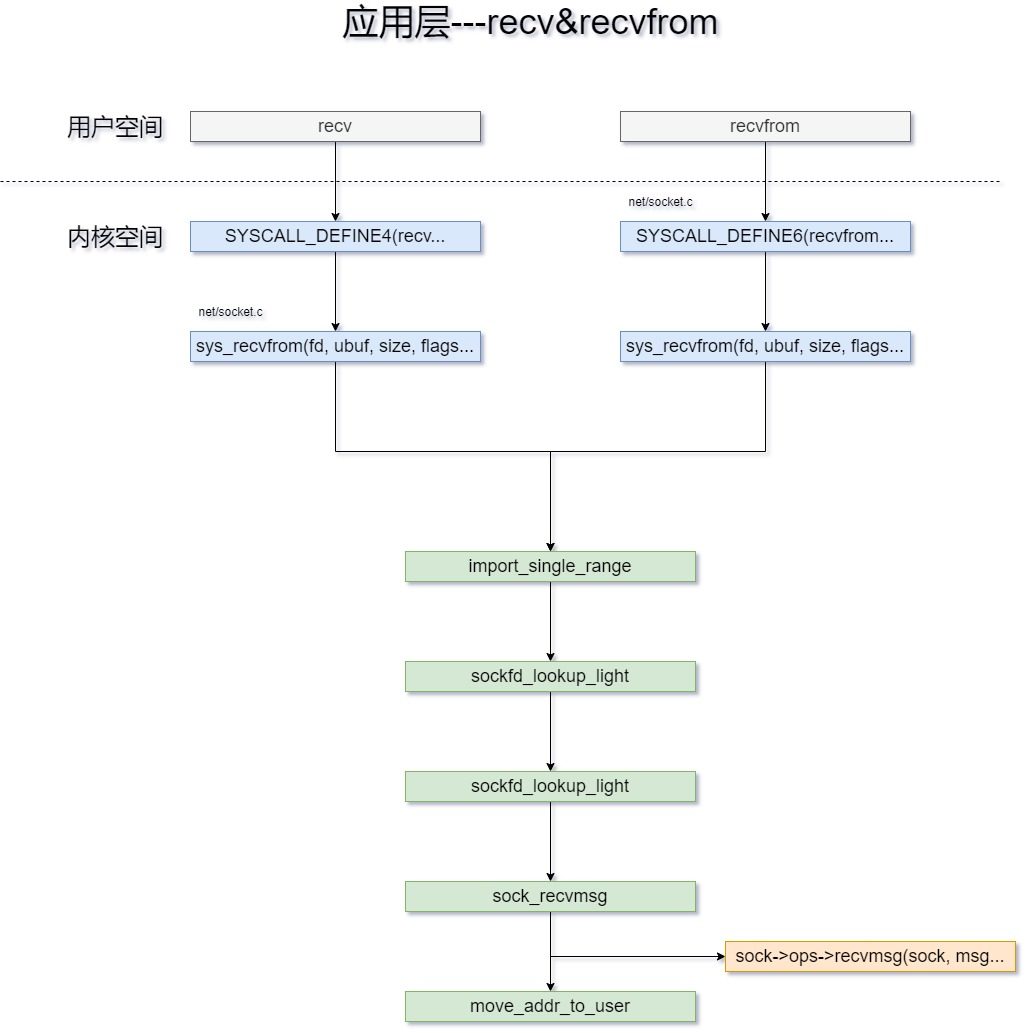
接下来,我们对每一步的具体工作内容进行分析。
当用户层调用
recv&recvfrom时,最终都会进入sys_recvfrom()函数,这个我们从recv函数的定义就可以看出;//pathname:net/socket.c /* * Receive a datagram from a socket. */ SYSCALL_DEFINE4(recv, int, fd, void __user *, ubuf, size_t, size, unsigned int, flags) { return sys_recvfrom(fd, ubuf, size, flags, NULL, NULL); }sys_recvfrom()函数的定义如下,在内核应用层我们主要通过这个函数来进行接收消息,这里主要工作如下:- 构建msghdr;
- 根据fd,找出对应的socket实例;
- 调用
sock_recvmsg函数,调用特定于协议的接收函数sock->ops->recvmsg()。例如TCP使用对应的tcp_recvmsg来进行接收; - 调用
move_addr_to_user,将数据从内核空间复制到用户空间;
//pathname:net/socket.c /* * Receive a frame from the socket and optionally record the address of the * sender. We verify the buffers are writable and if needed move the * sender address from kernel to user space. */ SYSCALL_DEFINE6(recvfrom, int, fd, void __user *, ubuf, size_t, size, unsigned int, flags, struct sockaddr __user *, addr, int __user *, addr_len) { struct socket *sock; struct iovec iov; struct msghdr msg; struct sockaddr_storage address; int err, err2; int fput_needed; err = import_single_range(READ, ubuf, size, &iov, &msg.msg_iter); if (unlikely(err)) return err; sock = sockfd_lookup_light(fd, &err, &fput_needed); if (!sock) goto out; msg.msg_control = NULL; msg.msg_controllen = 0; /* Save some cycles and don't copy the address if not needed */ msg.msg_name = addr ? (struct sockaddr *)&address : NULL; /* We assume all kernel code knows the size of sockaddr_storage */ msg.msg_namelen = 0; msg.msg_iocb = NULL; msg.msg_flags = 0; if (sock->file->f_flags & O_NONBLOCK) flags |= MSG_DONTWAIT; err = sock_recvmsg(sock, &msg, flags); if (err >= 0 && addr != NULL) { err2 = move_addr_to_user(&address, msg.msg_namelen, addr, addr_len); if (err2 < 0) err = err2; } fput_light(sock->file, fput_needed); out: return err; }import_single_range函数主要在这里实现构建msghdr的功能,函数定义如下。这里主要工作如下:- 判断buf的读写合法性,这是为了保护内核的安全设置的,同时使用
unlikely告诉编译器这个条件不太有可能发生,好让编译器对这个条件判断进行正确地优化; - 将buf和buf大小指向对象iov,这里实际指向的是struct msghdr msg.msg_iter,后续接收到的消息都在这里;
//pathname:lib/iov_iter.c int import_single_range(int rw, void __user *buf, size_t len, struct iovec *iov, struct iov_iter *i) { if (len > MAX_RW_COUNT) len = MAX_RW_COUNT; //判断buf的读写合法性 if (unlikely(!access_ok(!rw, buf, len))) return -EFAULT; //将buf和buf大小指向对象iov,这里实际指向的是struct msghdr msg.msg_iter iov->iov_base = buf; iov->iov_len = len; //填充其他字段 iov_iter_init(i, rw, iov, 1, len); return 0; }- 判断buf的读写合法性,这是为了保护内核的安全设置的,同时使用
填充完消息头之后,调用了
sockfd_lookup_light(),这里主要是根据文件描述符fd获取对应的socket实例。主要做的工作如下:调用fdget函数,根据文件描述符fd获取对应的
struct fd结构体实例;struct fd { struct file *file; unsigned int flags; };调用sock_from_file函数,返回file->private_data的值,这里主要指的是返回一个socket指针;
//pathname:net/socket.c struct socket *sock_from_file(struct file *file, int *err) { if (file->f_op == &socket_file_ops) return file->private_data; /* set in sock_map_fd */ *err = -ENOTSOCK; return NULL; }
//pathname:net/socket.c static struct socket *sockfd_lookup_light(int fd, int *err, int *fput_needed) { struct fd f = fdget(fd); struct socket *sock; *err = -EBADF; if (f.file) { sock = sock_from_file(f.file, err); if (likely(sock)) { *fput_needed = f.flags; return sock; } fdput(f); } return NULL; }当获取到对用的socket后,调用
sock_recvmsg函数,来根据特定的协议,调用具体的接收函数sock->ops->recvmsg。根据《深入理解Linux内核》中介绍,这里的接收消息处理逻辑如下:- 如果接收队列(通过sock结构的
receive_queue成员实现)上至少有一个分组,则移除并返回该分组; - 如果接收队列是空的,显然没有数据可以传递到用户进程。在这种情况下,进程使用
wait_for_packet使自身睡眠,直到数据到达; - 在新数据到达时,总是调用sock结构的
data_ready函数,因而进程可以在此时被唤醒;
//pathname:net/socket.c int sock_recvmsg(struct socket *sock, struct msghdr *msg, int flags) { //空函数,直接return 0 int err = security_socket_recvmsg(sock, msg, msg_data_left(msg), flags); return err ?: sock_recvmsg_nosec(sock, msg, flags); } static inline int sock_recvmsg_nosec(struct socket *sock, struct msghdr *msg, int flags) { return sock->ops->recvmsg(sock, msg, msg_data_left(msg), flags); }- 如果接收队列(通过sock结构的
当通过sock_recvmsg函数接收到数据后被唤醒,数据会被放在struct msghdr msg中,此时调用move_addr_to_user函数(实际其中主要是调用copy_to_user函数),将数据从内核空间拷贝至用户空间;
至此,一次socket的接收数据在内核应用层就完成了。
总结
最后,我们总结一下本节内容。
本节主要展示了在内核应用层一个socket如何被创建、发送和接收数据。大致内容包含如下:
创建socket
sys_socket()中,调用__sock_create()函数申请内存和注册当前协议到全局数组net_families[NPROTO];map_sock_fd主要用于对socket的file指针初始化,经过sock_map_fd()操作后,socket就通过其**file*指针与VFS管理的文件进行了关联,便可以进行文件的各种操作,如read、write、lseek、ioctl等;- 一个socket的创建就完成了,最终,返回到应用层的socket()就是一个socket的文件描述符;
发送数据
sys_send()和sys_sendto()函数一开始,就都进入了sys_sendto();- 发送时,填充要发送的内容到msg.msg_iter;
- 通过入参fd查找对应的socket;
- 组织消息,调用
sock_sendmsg来调 用 特 定 于 协 议 的 发 送 例 程sock->ops->sendmsg进行发送;
接收数据
接收数据和发送数据的流程比较相似。
- 当用户层调用
recv&recvfrom时,最终都会进入sys_recvfrom()函数; - 接收时,首先构建msghdr;
- 然后根据fd,找出对应的socket实例;
- 调用
sock_recvmsg函数,调用特定于协议的接收函数sock->ops->recvmsg()。例如TCP使用对应的tcp_recvmsg来进行接收; - 调用
move_addr_to_user,将数据从内核空间复制到用户空间;