在上一节我们介绍了内核网络在内核应用层以struct socket结构体的形式进行创建和传递。这一节,我们继续自上而下进行分析。
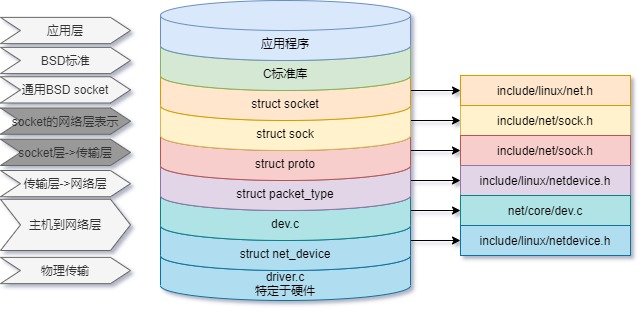
在进入传输层(UDP/TCP协议栈)之前,内核有一个INET协议族层,定义了struct sock结构体,将传输层的TCP/IP协议栈(struct proto)和应用层struct socket关联起来。
因为TCP协议的复杂性,我们很难在这里简单的在传输层进行分析,分析TCP协议也不是我们这里的重点,我们更关注整个Linux内核网络对数据的逐层处理,因此,我们这一节将在传输层选取UDP相关协议实现进行分析。
本节我们主要有两个任务:
- 分析传输层的发送流程;
- 分析传输层的接收流程
sock代替socket
在《深入Linux内核架构》中,作者这样描述了sock层的意义:“尽管尚未讨论sock结构,它不可避免地使人想到术语socket(套接字),这正是我们想要的,我们现在正处于应用层的边界上,数据迟早要使用套接字传输到用户空间,就像本章开头的示例程序那样。内核中有两种数据结构表示套接字,sock是到网络访问层的接口,而socket是到用户空间的接口”。因为我们这个系列文章是自上而下描述数据的流向,以一个数据socket的建立和数据的发送为起点进行分析,从应用层到底层的对数据进行追踪,而《深入Linux内核架构》网络部分是自下而上的。因此,我们和作者的视角刚好相反,虽然都在应用层的边界,我们是往下看的,先看到的是socket,再是sock。
在从应用层进入传输层时,内核中在net/ipv4/af_inet.c中struct sock结构体来表示上一层的socket,该层向下以sock格式与传输层的TCP/UDP协议连,向上以socket的格式与用户层进行数据传输。这里有一张图可以表示INET在内核中的位置和作用:
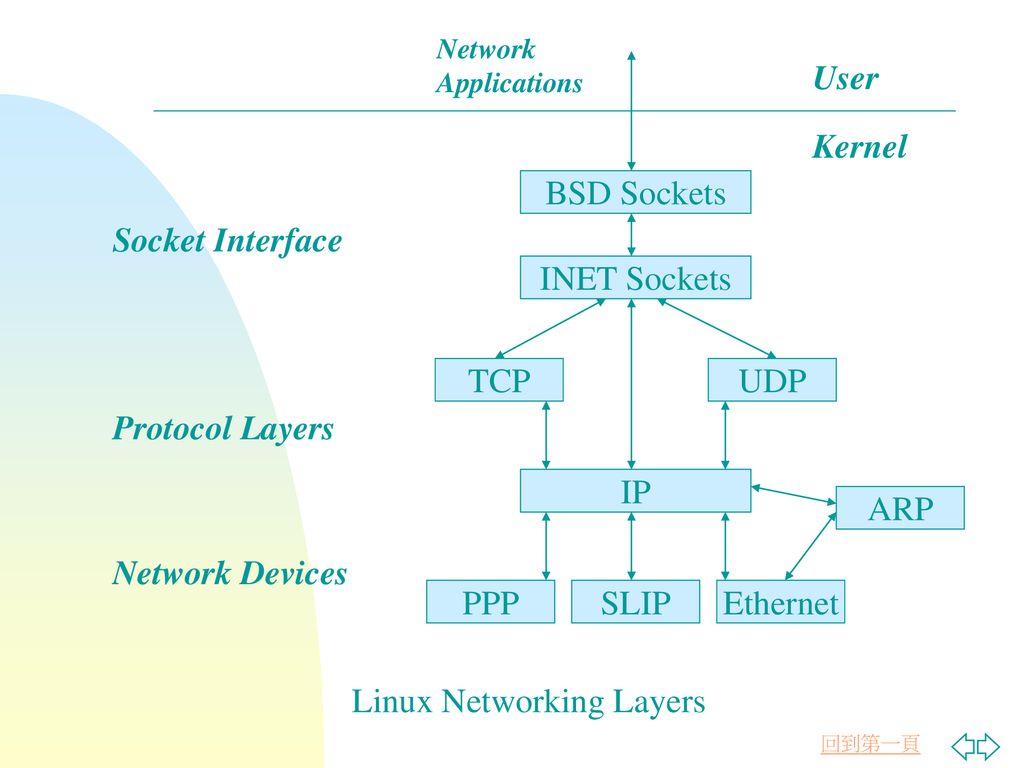
从上图可以看到,Linux内核网络的处理主要在协议层和网络设备驱动层,因此关于sock的收发接口我们这里就不做深入研究,这一节的主要内容我们还是直接进入UDP中研究它的发送数据和接收数据。
sock发送接口
int inet_sendmsg(struct socket *sock, struct msghdr *msg, size_t size)
{
struct sock *sk = sock->sk;
sock_rps_record_flow(sk);
/* We may need to bind the socket. */
if (!inet_sk(sk)->inet_num && !sk->sk_prot->no_autobind &&
inet_autobind(sk))
return -EAGAIN;
return sk->sk_prot->sendmsg(sk, msg, size);
}
sock接收数据
int inet_recvmsg(struct socket *sock, struct msghdr *msg, size_t size,
int flags)
{
struct sock *sk = sock->sk;
int addr_len = 0;
int err;
sock_rps_record_flow(sk);
err = sk->sk_prot->recvmsg(sk, msg, size, flags & MSG_DONTWAIT,
flags & ~MSG_DONTWAIT, &addr_len);
if (err >= 0)
msg->msg_namelen = addr_len;
return err;
}
传输层之UDP发送
传输层相较于应用层简单的数据检验,功能要复杂很多,我们这里选取相比之下更简单的UDP发送来进行分析。首先,这里接上一节的sendto发送流程图继续向下分析,我们可以得到如下调用图。
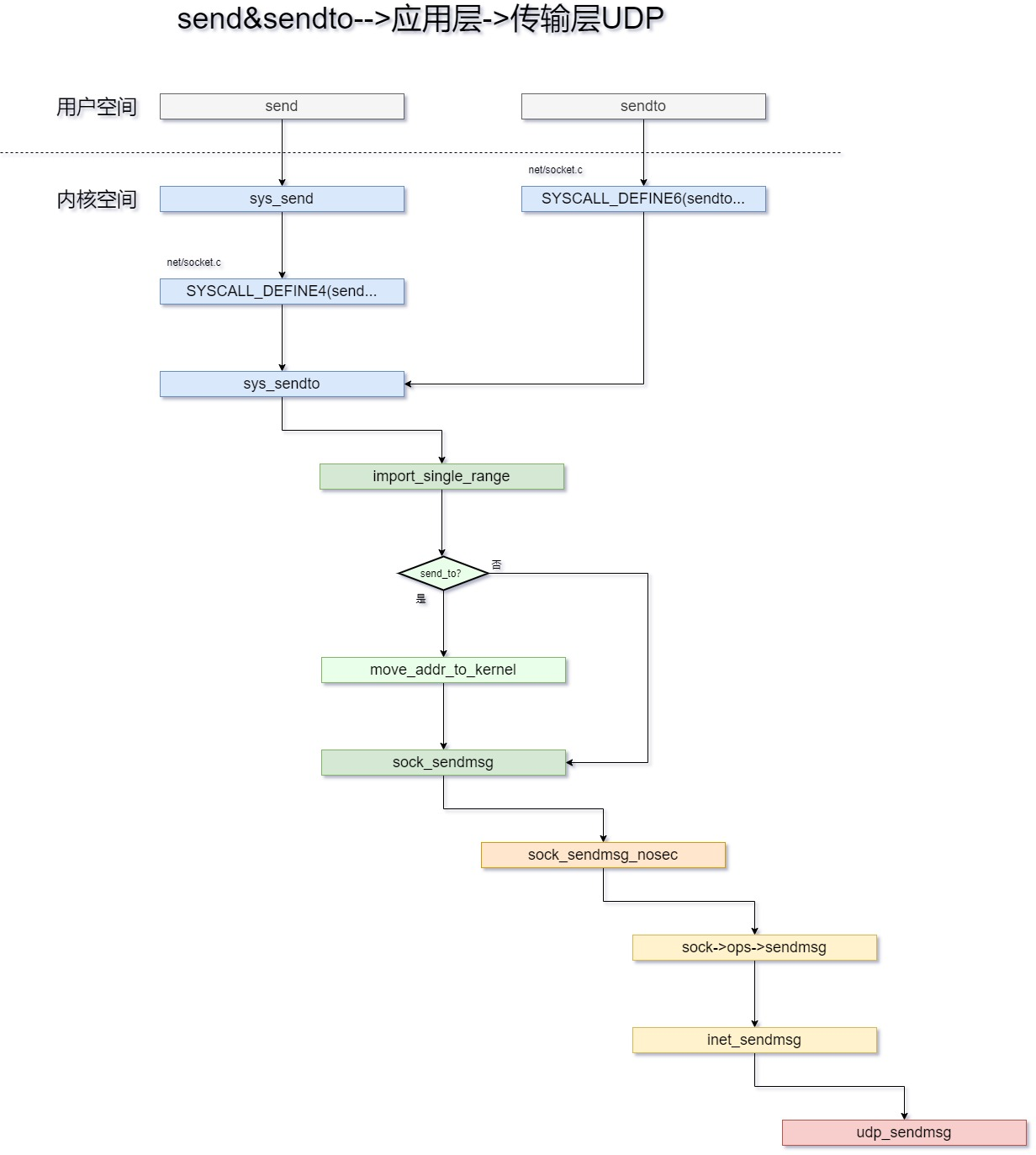
通过上图,我们可以看到在从INET协议族层之后,进入了传输层UDP协议层,该层发送入口是udp_sendmsg,这是一个比较长的函数我们接下来分析它,它的源代码位于net/ipv4/udp.c
检查corked
最开始,代码进行一些变量的赋值和flag的基本检查之后,检查了当前up->pending,当这个socket是被阻塞的时候,程序直接goto跳转至末尾的do_append_data处,这个我们稍后分析;
int udp_sendmsg(struct sock *sk, struct msghdr *msg, size_t len)
{
/*
* Check the flags.
*/
if (msg->msg_flags & MSG_OOB) /* Mirror BSD error message compatibility */
return -EOPNOTSUPP;
ipc.opt = NULL;
ipc.tx_flags = 0;
ipc.ttl = 0;
ipc.tos = -1;
getfrag = is_udplite ? udplite_getfrag : ip_generic_getfrag;
fl4 = &inet->cork.fl.u.ip4;
if (up->pending) {
/*
* There are pending frames.
* The socket lock must be held while it's corked.
*/
lock_sock(sk);
if (likely(up->pending)) {
if (unlikely(up->pending != AF_INET)) {
release_sock(sk);
return -EINVAL;
}
goto do_append_data;
}
release_sock(sk);
}
这里将socket设置成阻塞corked有2个途径:
- 通过
setsockopt系统调用设置socket的UDP_CORK配置项; - 在程序中调用
send、sendto和sendmsg时,通过设置flags的MSG_MORE选项进行指定;
获取socket目的地址和端口
socket的目的地址可能有2个来源:
socket由于在某个时刻被connect,它本身存储有目的地址和端口;- 地址被通过辅助结构体传递,例如我们看到的
sendto调用的时候,会进行指定;
接下来,我们看内核中的处理;
/* * Get and verify the address. */ if (msg->msg_name) { DECLARE_SOCKADDR(struct sockaddr_in *, usin, msg->msg_name); if (msg->msg_namelen < sizeof(*usin)) return -EINVAL; if (usin->sin_family != AF_INET) { if (usin->sin_family != AF_UNSPEC) return -EAFNOSUPPORT; } daddr = usin->sin_addr.s_addr; dport = usin->sin_port; if (dport == 0) return -EINVAL; } else { if (sk->sk_state != TCP_ESTABLISHED) return -EDESTADDRREQ; daddr = inet->inet_daddr; dport = inet->inet_dport; /* Open fast path for connected socket. Route will not be used, if at least one option is set. */ connected = 1; }在之前,我们调用sendto接口的时候,内核中填充了一个结构体struct msghdr,这里展示的就是如何解析这个结构体,来获取其中的目的地址和端口;
如果在到达这个函数的时候,内核没有安排一个
struct msghdr,也就无法从上一步中解析出地址和端口,我们就进入了else的判断范围,这里UDP协议中有一个TCP_ESTABLISHED,用来描述一个socket的好坏,如果是被连接的socket,这里也可以获取目的地址和端口,并且将connected标志位置为1;
bookkeeping和时间戳
接下来,源地址、设备号、时间戳选项将被设置(SOCK_TIMESTAMPING_TX_HARDWARE
,SOCK_TIMESTAMPING_TX_SOFTWARE,SOCK_WIFI_STATUS)。ipc.sockc.tsflags = sk->sk_tsflags; ipc.addr = inet->inet_saddr; ipc.oif = sk->sk_bound_dev_if;
Ancillary messages辅助数据
sendmsg和recvmsg允许用户除了发送和接收packets之外,还可以设置辅助数据;用户可以制作一个struct msghdr结构体,将ancillary data嵌入进去。辅助数据的格式见这里。
一个比较受欢迎的例子是IP_PKTINFO,在这种情况下,sendmsg发送数据的时候允许用户设置struct in_pktinfo,该进程可以通过填写结构in_pktinfo结构中的字段来指定要在数据包上使用的源地址。这对于一个有多个IP的服务端,是一个有用的设计。这样,服务端就可以使用客户端连接的IP进行回复。
类似的,当用户调用了sendmsg发送数据的时候,还可以使用IP_TTL和IP_TOS来设置每一包数据的TTL和TOS,请注意,可以使用 setsockopt 在所有传出数据包的套接字级别设置IP_TTL和IP_TOS,而不是根据需要按数据包进行设置。Linux内核通过一个数组将TOS转换为优先级;优先级影响了数据从排队队列被发送的时间和方式。
我们可以看到这里UDP协议处理辅助数据:
if (msg->msg_controllen) {
err = ip_cmsg_send(sk, msg, &ipc, sk->sk_family == AF_INET6);
if (unlikely(err)) {
kfree(ipc.opt);
return err;
}
if (ipc.opt)
free = 1;
connected = 0;
}
内核中通过ip_cmsg_send来解析ancillary message,源代码在这里。
这里只要提供了辅助数据,就要把connected标记为未连接0.
自定义IP选项
接下来,sendmsg将检查用户是否通过辅助数据(Ancillary messages)指定了IP选项。如果选项被设置,则被使用。否则,使用socket中已经存在的选项;
if (!ipc.opt) { struct ip_options_rcu *inet_opt; rcu_read_lock(); inet_opt = rcu_dereference(inet->inet_opt); if (inet_opt) { memcpy(&opt_copy, inet_opt, sizeof(*inet_opt) + inet_opt->opt.optlen); ipc.opt = &opt_copy.opt; } rcu_read_unlock(); }检查源路由记录,有2个源路由记录的类型:LSR和SSR如果设置了此选项,则第一个跃点地址将被记录并存储为
faddr,并且套接字将标记为“未连接”;if (ipc.opt && ipc.opt->opt.srr) { if (!daddr) return -EINVAL; faddr = ipc.opt->opt.faddr; connected = 0; }处理 SRR 选项后,将从用户通过辅助消息设置的值或套接字当前正在使用的值中检索 TOS IP 标志。后跟检查:
- SO_DONTROUTE标准,setsockopt来设置,或者
- MSG_DONTROUTE被设置,当使用sendto和sendmsg时或者
- is_strictroute被设置,表示需要严格的源记录路由;
然后,tos的标志位
0x1(RTO_ONLINK)被设置,connected被标志为未连接;tos = get_rttos(&ipc, inet); if (sock_flag(sk, SOCK_LOCALROUTE) || (msg->msg_flags & MSG_DONTROUTE) || (ipc.opt && ipc.opt->opt.is_strictroute)) { tos |= RTO_ONLINK; connected = 0; }
多播还是单拨?
接下来,代码试图处理多播(组播)。这是一个棘手的问题,因为用户可以通过发送辅助IP_PKTINFO消息来指定从何处发送数据包的备用源地址或设备索引,如前所述。
如果目的地址是组播地址。
- 写入packet的设备索引将被设置为组播设备索引;
- packet上的源地址将被设置为组播源地址。
如果用户没有通过IP_PKTINFO来覆盖索引,则是如下处理:
if (ipv4_is_multicast(daddr)) {
if (!ipc.oif)
ipc.oif = inet->mc_index;
if (!saddr)
saddr = inet->mc_addr;
connected = 0;
} else if (!ipc.oif)
ipc.oif = inet->uc_index;
如果不是组播,则直接设置用户索引inet->uc_index。除非用户使用IP_PKTINFO来指定。
路由
如果socket的connected状态是连接的1,则使用一个快的路径来获取路由结构体。
if (connected)
rt = (struct rtable *)sk_dst_check(sk, 0);
如果套接字未连接,或者sk_dst_check检查确定路由已过时,则划入一个慢的路径生成一个新的路由结构。通过调用flowi4_init_output来为这个UDP流构建一个结构体。
if (!rt) {
struct net *net = sock_net(sk);
__u8 flow_flags = inet_sk_flowi_flags(sk);
fl4 = &fl4_stack;
flowi4_init_output(fl4, ipc.oif, sk->sk_mark, tos,
RT_SCOPE_UNIVERSE, sk->sk_protocol,
flow_flags,
faddr, saddr, dport, inet->inet_sport);
构建此流结构后,套接字及其流结构将传递到安全子系统,以便 SELinux 或 SMACK 等系统可以在流结构上设置安全 ID 值。接下来,ip_route_output_flow将调用 IP 路由代码,为此流生成路由结构:
security_sk_classify_flow(sk, flowi4_to_flowi(fl4));
rt = ip_route_output_flow(net, fl4, sk);
if (IS_ERR(rt)) {
err = PTR_ERR(rt);
rt = NULL;
if (err == -ENETUNREACH)
IP_INC_STATS(net, IPSTATS_MIB_OUTNOROUTES);
goto out;
}
在下来这个位置,保存统计计数器和其他计数器。其含义将在下面UDP监视部分讨论。
接下来,如果路由被设置为广播,但是socket的SOCK_BROADCAST选项没有被设置,则代码终止。如果socket被认为是“connected”的,则将路由结构缓存下来。
err = -EACCES;
if ((rt->rt_flags & RTCF_BROADCAST) &&
!sock_flag(sk, SOCK_BROADCAST))
goto out;
if (connected)
sk_dst_set(sk, dst_clone(&rt->dst));
防止ARP缓存引起的MSG_CONFIRM过时
如果用户调用send、sendto或者sendmsg的时候,指定了MSG_CONFIRM标志,协议层将进行处理:
if (msg->msg_flags&MSG_CONFIRM)
goto do_confirm;
back_from_confirm:
这个标志指示系统验证ARP是否有效,并防止对其进行垃圾回收。dst_confirm函数只是在目标缓存条目上设置一个标志,当查询相邻缓存并找到条目时,将在很久以后检查该标志。我们稍后会再次看到这一点。此功能通常用于 UDP 网络应用进程,以减少不必要的 ARP 流量。do_confirm标签位于此函数的末尾附近,但它很简单:
do_confirm:
dst_confirm(&rt->dst);
if (!(msg->msg_flags&MSG_PROBE) || len)
goto back_from_confirm;
err = 0;
goto out;
如果不是probe,验证完cache的条目后,返回back_from_confirm;
一旦do_confirm返回到back_from_confirm,开始处理UDP corked的问题。
uncorked UDP sockets快速路径:准备传输数据
如果UDP未请求corked,数据可以被打包到struct sk_buff,然后通过udp_send_skb发送到IP协议层。这是通过调用ip_make_skb来完成的。
通过ip_route_output_flow生成的路由结构也会被传入,它将附着在skb中,之后在IP协议层使用。
/* Lockless fast path for the non-corking case. */
if (!corkreq) {
skb = ip_make_skb(sk, fl4, getfrag, msg, ulen,
sizeof(struct udphdr), &ipc, &rt,
msg->msg_flags);
err = PTR_ERR(skb);
if (!IS_ERR_OR_NULL(skb))
err = udp_send_skb(skb, fl4);
goto out;
}
ip_make_skb函数将尝试构建一个skb,同时考虑到广泛的因素,例如:
传输数据
如果没有发生错误,udp_send_skb来处理skb,将数据传入到协议栈的下一层,也就是IP协议栈。
如果发生了 错误,错误将被记录,这里我们没有深入研究。
err = PTR_ERR(skb);
if (!IS_ERR_OR_NULL(skb))
err = udp_send_skb(skb, fl4);
corkingUDP sockets慢速路径
如果UDP socket被corked,同时先前数据没有被阻塞住,慢速路径开启:
- LOCK这个socket;
- 检查应用错误bug:一个已经corked的socket被重复corked;
- cork the socket
- pend data
lock_sock(sk);
if (unlikely(up->pending)) {
/* The socket is already corked while preparing it. */
/* ... which is an evident application bug. --ANK */
release_sock(sk);
net_dbg_ratelimited("cork app bug 2\n");
err = -EINVAL;
goto out;
}
/*
* Now cork the socket to pend data.
*/
fl4 = &inet->cork.fl.u.ip4;
fl4->daddr = daddr;
fl4->saddr = saddr;
fl4->fl4_dport = dport;
fl4->fl4_sport = inet->inet_sport;
up->pending = AF_INET;
do_append_data:
up->len += ulen;
err = ip_append_data(sk, fl4, getfrag, msg, ulen,
sizeof(struct udphdr), &ipc, &rt,
corkreq ? msg->msg_flags|MSG_MORE : msg->msg_flags);
if (err)
udp_flush_pending_frames(sk);
else if (!corkreq)
err = udp_push_pending_frames(sk);
else if (unlikely(skb_queue_empty(&sk->sk_write_queue)))
up->pending = 0;
release_sock(sk);
传输层之UDP接收
在UDP层接收之前数据大致的流向如下:
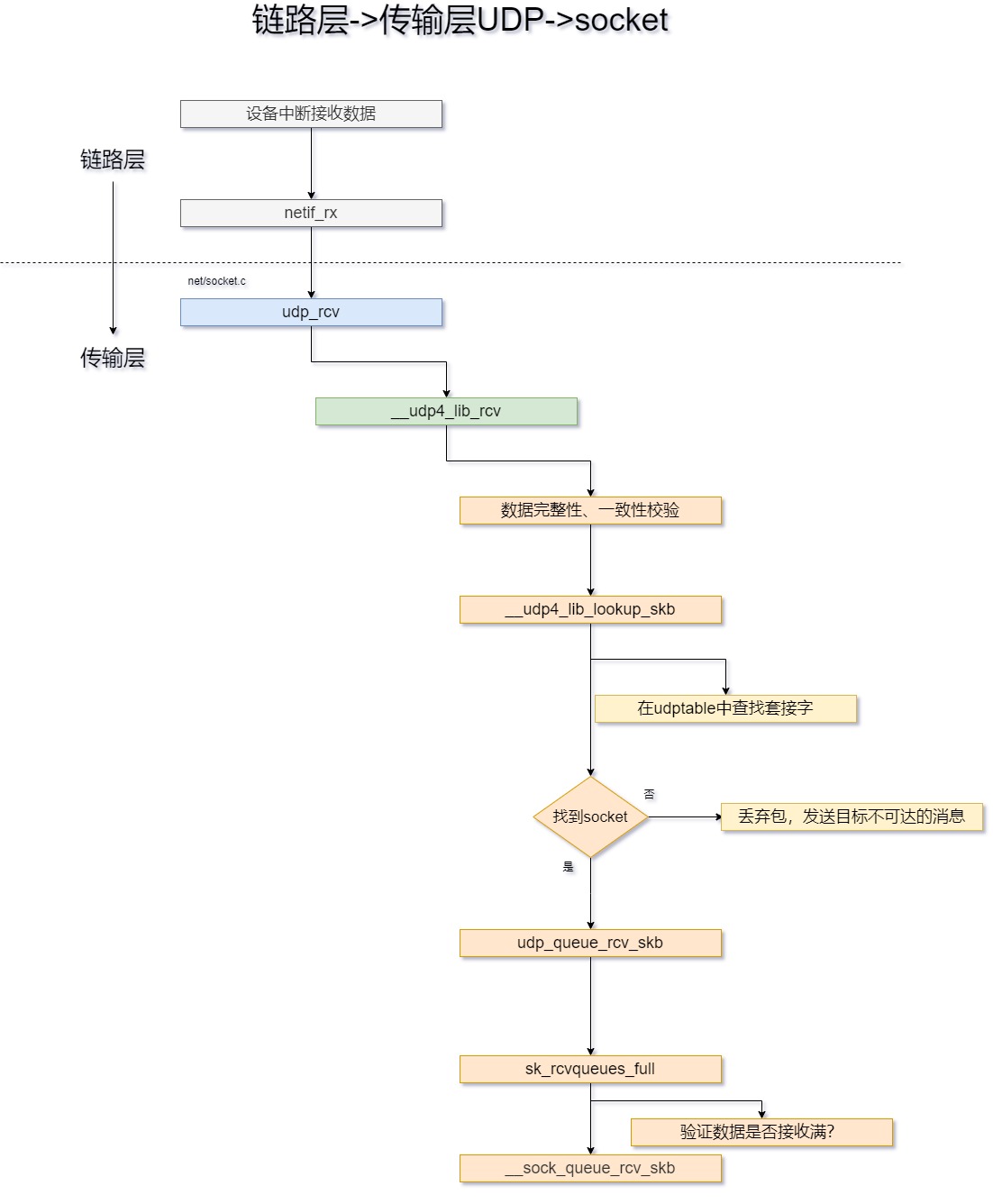
udp_rcv
udp_rcv的实现是在udp.c;这里只有简单一行去调用
__udp4_lib_rcv;
__udp4_lib_rcv
__udp4_lib_rcv函数检查packet是否有效,然后获取UDP头、UDP数据报文长度、源地址和目的地址。接下来,会进行完整性检查和数据的校验。
在IP协议层,数据报文被优化,加上了dst_entry数据然后传递到了UDP协议层。
如果一个socket的dst_entry被找到,则__udp4_lib_rcv 将排队UDP数据包到socket;
sk = skb_steal_sock(skb);
if (sk) {
struct dst_entry *dst = skb_dst(skb);
int ret;
if (unlikely(sk->sk_rx_dst != dst))
udp_sk_rx_dst_set(sk, dst);
ret = udp_queue_rcv_skb(sk, skb);
sock_put(sk);
/* a return value > 0 means to resubmit the input, but
* it wants the return to be -protocol, or 0
*/
if (ret > 0)
return -ret;
return 0;
}
如果没有从early_demux操作连接套接字,则现在将通过调用__udp4_lib_lookup_skb来查找接收套接字。
if (rt->rt_flags & (RTCF_BROADCAST|RTCF_MULTICAST))
return __udp4_lib_mcast_deliver(net, skb, uh,
saddr, daddr, udptable, proto);
sk = __udp4_lib_lookup_skb(skb, uh->source, uh->dest, udptable);
if (sk) {
int ret;
if (inet_get_convert_csum(sk) && uh->check && !IS_UDPLITE(sk))
skb_checksum_try_convert(skb, IPPROTO_UDP, uh->check,
inet_compute_pseudo);
ret = udp_queue_rcv_skb(sk, skb);
/* a return value > 0 means to resubmit the input, but
* it wants the return to be -protocol, or 0
*/
if (ret > 0)
return -ret;
return 0;
}
在上述两种情况下,数据包都将被排队到socket;
ret = udp_queue_rcv_skb(sk, skb);
sock_put(sk);
如果socket没有匹配上,或者校验和错误,则丢弃当前packet;
/* No socket. Drop packet silently, if checksum is wrong */
if (udp_lib_checksum_complete(skb))
goto csum_error;
__UDP_INC_STATS(net, UDP_MIB_NOPORTS, proto == IPPROTO_UDPLITE);
icmp_send(skb, ICMP_DEST_UNREACH, ICMP_PORT_UNREACH, 0);
udp_queue_rcv_skb
此函数初始化部分如下所示:
- 确定该数据包关联的套接字是否为封装套接字,如果是,将数据传递到该层的处理函数;
- 确定该数据包是否是UDP-Lite数据,然后做完整的检查;
- 验证数据校验和,如果验证失败,则丢弃;
最后,我们到达接收队列逻辑,该逻辑首先检查套接字的接收队列是否已满。/net/ipv4/udp.c
if (sk_rcvqueues_full(sk, sk->sk_rcvbuf))
{
__UDP_INC_STATS(sock_net(sk), UDP_MIB_RCVBUFERRORS,
is_udplite);
goto drop;
}
sk_rcvqueues_full
sk_rcvqueues_full函数的功能是检查socket积压的数据长度,socket的sk_rmem_alloc来确定总长度是否超过sk_rcvbuf(就是上边代码片段的sk->sk_rcvbuf)。
/*
* Take into account size of receive queue and backlog queue
* Do not take into account this skb truesize,
* to allow even a single big packet to come.
*/
static inline bool sk_rcvqueues_full(const struct sock *sk, unsigned int limit)
{
unsigned int qsize = sk->sk_backlog.len + atomic_read(&sk->sk_rmem_alloc);
return qsize > limit;
}
udp_queue_rcv_skb
现在已经验证了数据没有接收满,在这里继续处理数据报文。
bh_lock_sock(sk);
if (!sock_owned_by_user(sk))
rc = __udp_queue_rcv_skb(sk, skb);
else if (sk_add_backlog(sk, skb, sk->sk_rcvbuf))
{
bh_unlock_sock(sk);
goto drop;
}
bh_unlock_sock(sk);
return rc;
这里第一步先确定socket是否有来自用户空间的系统调:
- 如果没有,则通过调用
__udp_queue_rcv_skb加入到接收队列; - 如果有,调用
sk_add_backlog先暂存数据;
函数__udp_queue_rcv_skb调用__sock_queue_rcv_skb增加数据包到接收队列,如果无法将数据报添加到套接字的接收队列中,则碰撞统计信息计数器。
int __udp_queue_rcv_skb(struct sock *sk, struct sk_buff *skb)
{
int rc;
if (inet_sk(sk)->inet_daddr)
{
sock_rps_save_rxhash(sk, skb);
sk_mark_napi_id(sk, skb);
sk_incoming_cpu_update(sk);
}
rc = __sock_queue_rcv_skb(sk, skb);
if (rc < 0)
{
int is_udplite = IS_UDPLITE(sk);
/* Note that an ENOMEM error is charged twice */
if (rc == -ENOMEM)
UDP_INC_STATS(sock_net(sk), UDP_MIB_RCVBUFERRORS,
is_udplite);
UDP_INC_STATS(sock_net(sk), UDP_MIB_INERRORS, is_udplite);
kfree_skb(skb);
trace_udp_fail_queue_rcv_skb(rc, sk);
return -1;
}
return 0;
}
网络数据通过 sock_queue_rcv 进入 socket 的接收队列。这个函数在将数据报最终送到接收队列之前,会做几件事情:
- 检查 socket 已分配的内存,如果超过了 receive buffer 的大小,丢弃这个包并更新计数;
- 等待通过套接字交付数据的进程,在
sk_sleep等待队列上睡眠; - 调用
__skb_queue_tail将包含分组数据的的套接字缓冲区插入到sk_receive_queue链表末端,其表头保存在特定于套接字的sock结构中; - 调用
sk_data_ready指向的函数(如果用标准函数sock_init_data来初始化sock实例,通常是sock_def_readable),通知套接字有新数据到达。这会唤醒在sk_sleep队列上睡眠、等待数据到达的所有进程。
最后,所有在这个 socket 上等待数据的进程都收到一个通知,通过 sk_data_ready 通知处理函数
【参考文献】:
- Monitoring and Tuning the Linux Networking Stack: Sending Data
- Monitoring and Tuning the Linux Networking Stack: Receiving Data
- LINUX内核网络中数据报在协议层的处理
- Professional linux kernel architecture. (2010). 深入Linux内核架构. 人民邮电出版社.