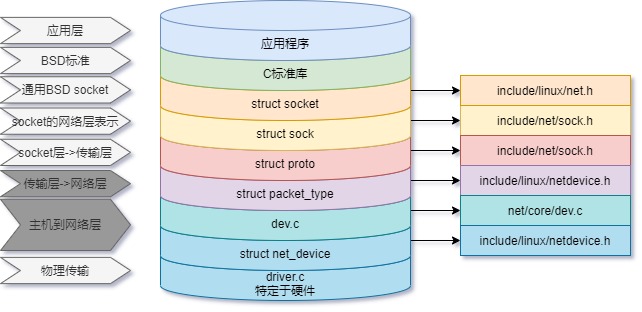
终于又有时间划水了,我们接着分析网络层。在上一节中,我们介绍了sock与传输层UDP,展示了在传输层(UDP协议栈)中的数据收发流。
本节,继续自上而下进行跟踪,紧挨着传输层的是网络层(我们这里主要关注IPv4协议)。网络层主要负责如下工作:
- 本机发送和接收数据;
- 其他经过网卡设备的数据转发;
我们这里主要关注网络层对本机ipv4数据的发送和接收处理,跟踪内核代码,了解数据是如何从传输层(UDP协议)经过**网络层(IP协议)**发送到网卡设备;同时,也会跟踪数据从网卡接收到之后,经过网络层(IP协议)进入udp的接收入口;最后,会在篇幅允许的情况下,了解网络层如何转发经过网卡非本机的数据。
网络层的数据和路线
ipv4协议首部
IPv4报头成员的内容决定了IPv4协议栈处理数据包的方式,如果存在问题,则数据包将被丢弃。
在*《TCP-IP详解卷I-协议》IP:网际协议*一章节中,我们挪用了这一章节中的IP数据包的结构,如下图:

IP报头的定义位于文件ip.h,位于这样一个结构体中:
struct iphdr {
#if defined(__LITTLE_ENDIAN_BITFIELD)
__u8 ihl:4,
version:4;
#elif defined (__BIG_ENDIAN_BITFIELD)
__u8 version:4,
ihl:4;
#else
#error "Please fix <asm/byteorder.h>"
#endif
__u8 tos;
__be16 tot_len;
__be16 id;
__be16 frag_off;
__u8 ttl;
__u8 protocol;
__sum16 check;
__be32 saddr;
__be32 daddr;
/*The options start here. */
};
各部分含义如下:
- **ihl:**表示Internet报头长度。IPv4报头长度以4字节为单位,长度不固定。因为IPv4报头可包含可选的边长选项。IPv4报头最短为20字节(不包含任何选项时,对应的ihl的值为5),最长为60字节(对应的ihl值为15).IPv4报头的长度必须是4字节的整数倍。
- **version:**必须是4。
- **tos:**tos表示服务类型。
- **tot_len:**包括报头在内的数据包总长度,单位为字节。tot_len字段长16位,可表示最大长度为64KB。RFC 761规定,数据包最短不得少于576字节。
- **id:**IPv4报头标识。对于分段来说,id字段很重要。对SKB进行分段时,所有分段的id值都必须相同;对于分段后的数据包,则要根据各个分段的id对其进行重组。
- **frag_off:**分段偏移量,长16位。后13位指出了分段的偏移量。在第一个分段中,偏移量为0。偏移量以8字节为单位。前3位的值不同时,分别表示如下含义:
- 001表示后边还有其他分段(More fragments,MF).除最后一个分段外,其他分段都必须设置这个标志;
- 010表示不分段(Don’t Fragment,DF).
- 100表示拥塞(Congestion,CE).
- **ttl:**存活时间。这是一个 跳数计数器。每个转发节点都会将ttl减1,当ttl变为0时,将丢弃数据包,并发回一条ICMPv4超时消息,以避免数据包因某种原因被无休止的转发。
- **protocol:**数据包的第4层协议,如IPPROTO_TCP表示TCP流量,而IPPROTO_UDP表示UDP流量。
- **check:**校验和,长16位。校验和是仅根据IPv4报头计算得到的。
- **saddr:**源IPv4地址,长32位。
- **daddr:**目标IPv4地址,长32位。
IPV4的初始化
IPv4数据包的以太类型为0x0800(以太类型存储在14字节的以太网报头的开头两个字节中)。每种协议都必须指定一个协议处理程序并初始化,以便让网络栈能够处理归属于该协议的数据包。本机介绍的IPv4协议处理程序的注册,让读者了解导致IPv4方法对收到的IPv4数据包进行处理的起因。(也就是在这儿注册了IPv4接收回调函数)
程序部分:
static struct packet_type ip_packet_type __read_mostly = {
.type = cpu_to_be16(ETH_P_IP),
.func = ip_rcv,
.list_func = ip_list_rcv,
};
static int __init inet_init(void)
{
......
dev_add_pack(&ip_packet_type);
......
}
dev_add_pack()将ip_rcv()指定为IPv4数据包的协议处理程序。inet_init()执行各种IPv4初始化工作,在引导阶段被调用。
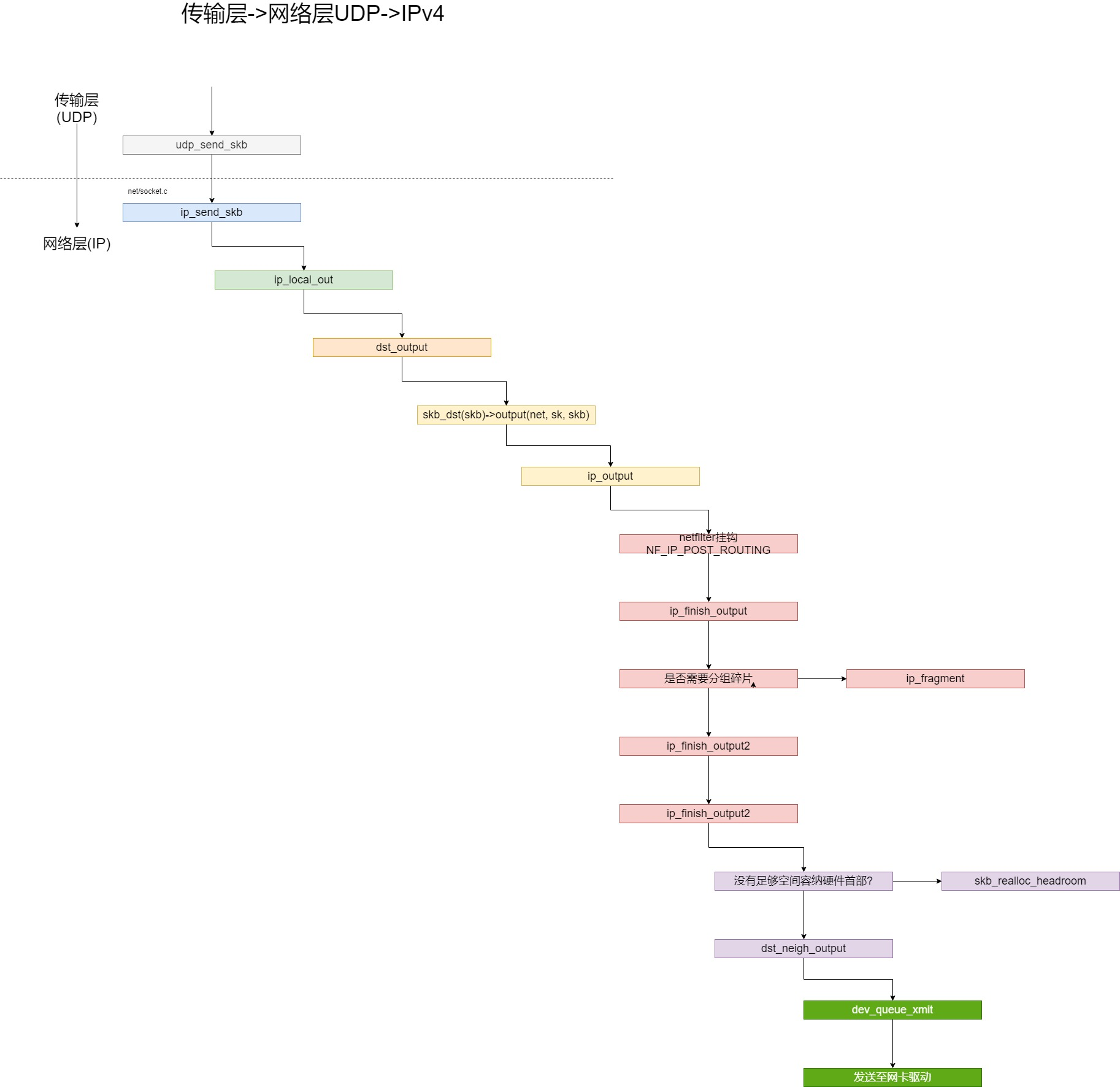
本机发送数据
从上一节我们知道,在UDP协议发送数据最后,由"udp_send_skb来处理skb,将数据传入到协议栈的下一层,也就是IP协议栈",因此,我们这里从udp_send_skb()开始入手。
这里大致画了一张UDP数据在IP协议层的流向,来展示数据的发送过程:
 本机接收数据ip_rcv
本机接收数据ip_rcv
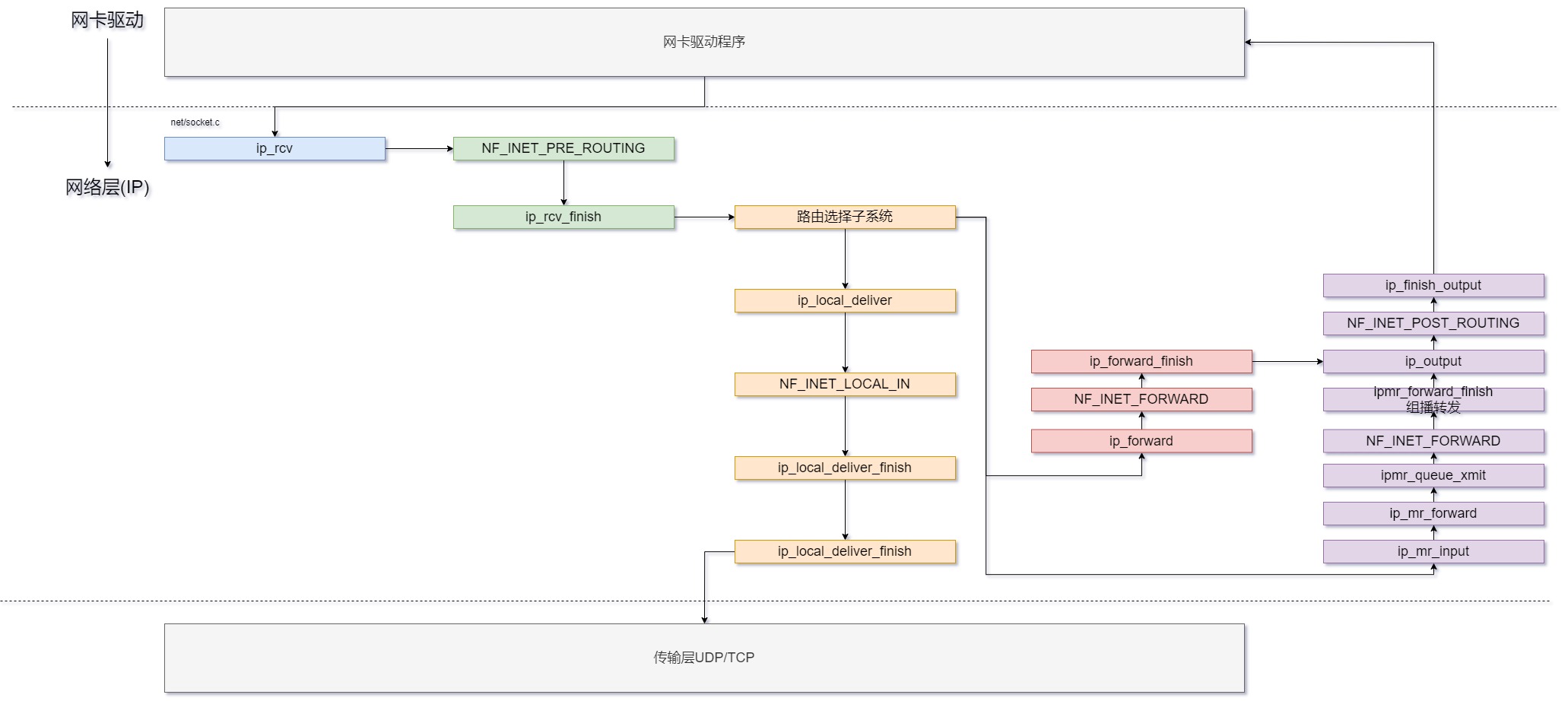
ip_rcv
该函数的定义位于文件ip_input.c。ip_rcv()主要完成数据包的完整性检查,实际的工作通过ip_rcv_finish()来完成。
- 判断是其他主机的数据包,则丢弃;
- 检查IPv4的包头大小和版本;
- 调用钩子函数NF_INET_PRE_ROUTING,我们这里假设没有调用,直接调用下一个函数ip_rcv_finish,真正处理数据。
/*
* Main IP Receive routine.
*/
int ip_rcv(struct sk_buff *skb, struct net_device *dev, struct packet_type *pt, struct net_device *orig_dev)
{
const struct iphdr *iph;
struct net *net;
u32 len;
/* When the interface is in promisc. mode, drop all the crap
* that it receives, do not try to analyse it.
*/
/* 判断是其他主机的数据包,则丢弃;*/
if (skb->pkt_type == PACKET_OTHERHOST)
goto drop;
net = dev_net(dev);
__IP_UPD_PO_STATS(net, IPSTATS_MIB_IN, skb->len);
skb = skb_share_check(skb, GFP_ATOMIC);
if (!skb) {
__IP_INC_STATS(net, IPSTATS_MIB_INDISCARDS);
goto out;
}
if (!pskb_may_pull(skb, sizeof(struct iphdr)))
goto inhdr_error;
iph = ip_hdr(skb);
/*
* RFC1122: 3.2.1.2 MUST silently discard any IP frame that fails the checksum.
*
* Is the datagram acceptable?
*
* 1. Length at least the size of an ip header
* 2. Version of 4
* 3. Checksums correctly. [Speed optimisation for later, skip loopback checksums]
* 4. Doesn't have a bogus length
*/
/* 检查IPv4的包头大小和版本 */
if (iph->ihl < 5 || iph->version != 4)
goto inhdr_error;
BUILD_BUG_ON(IPSTATS_MIB_ECT1PKTS != IPSTATS_MIB_NOECTPKTS + INET_ECN_ECT_1);
BUILD_BUG_ON(IPSTATS_MIB_ECT0PKTS != IPSTATS_MIB_NOECTPKTS + INET_ECN_ECT_0);
BUILD_BUG_ON(IPSTATS_MIB_CEPKTS != IPSTATS_MIB_NOECTPKTS + INET_ECN_CE);
__IP_ADD_STATS(net,
IPSTATS_MIB_NOECTPKTS + (iph->tos & INET_ECN_MASK),
max_t(unsigned short, 1, skb_shinfo(skb)->gso_segs));
if (!pskb_may_pull(skb, iph->ihl*4))
goto inhdr_error;
iph = ip_hdr(skb);
if (unlikely(ip_fast_csum((u8 *)iph, iph->ihl)))
goto csum_error;
len = ntohs(iph->tot_len);
if (skb->len < len) {
__IP_INC_STATS(net, IPSTATS_MIB_INTRUNCATEDPKTS);
goto drop;
} else if (len < (iph->ihl*4))
goto inhdr_error;
/* Our transport medium may have padded the buffer out. Now we know it
* is IP we can trim to the true length of the frame.
* Note this now means skb->len holds ntohs(iph->tot_len).
*/
if (pskb_trim_rcsum(skb, len)) {
__IP_INC_STATS(net, IPSTATS_MIB_INDISCARDS);
goto drop;
}
skb->transport_header = skb->network_header + iph->ihl*4;
/* Remove any debris in the socket control block */
memset(IPCB(skb), 0, sizeof(struct inet_skb_parm));
IPCB(skb)->iif = skb->skb_iif;
/* Must drop socket now because of tproxy. */
skb_orphan(skb);
/* 调用钩子函数NF_INET_PRE_ROUTING,我们这里假设没有调用,直接调用下一个函数ip_rcv_finish,真正处理数据*/
return NF_HOOK(NFPROTO_IPV4, NF_INET_PRE_ROUTING,
net, NULL, skb, dev, NULL,
ip_rcv_finish);
csum_error:
__IP_INC_STATS(net, IPSTATS_MIB_CSUMERRORS);
inhdr_error:
__IP_INC_STATS(net, IPSTATS_MIB_INHDRERRORS);
drop:
kfree_skb(skb);
out:
return NET_RX_DROP;
}
ip_rcv_finish
- skb_dst()用于检查是否有与skb相关联dst对象,dst是一个dst_entry实例,表示路由选择子系统的查找结果。
- 如果没有与
SKB关联的dst,则由ip_route_input_noref()在路由选择子系统中执行查找,如果查找失败,数据包被丢弃;在ip_route_input_noref()中,查找工作是根据路由选择表和数据包头进行的。在路由选择子系统中查找时,也会设置dst的input和output回调函数。例如,如果需要对数据包进行准发,在路由选择子系统查找时把input回调设置成ip_forward();如果目的是当前机器,则input是为ip_local_deliver();如果是组播,则input回调设置为ip_mr_input()。也就是dst决定了数据包的后续走向。 - 检查IPv4报头是否包含选项;
- 通过
dst_input,调用skb_dst(skb)->input(skb)将数据传输到上一层。
static int ip_rcv_finish(struct net *net, struct sock *sk, struct sk_buff *skb)
{
const struct iphdr *iph = ip_hdr(skb);
struct rtable *rt;
struct net_device *dev = skb->dev;
/* if ingress device is enslaved to an L3 master device pass the
* skb to its handler for processing
*/
skb = l3mdev_ip_rcv(skb);
if (!skb)
return NET_RX_SUCCESS;
/*skb_dst()用于检查是否有与skb相关联dst对象*/
if (net->ipv4.sysctl_ip_early_demux &&
!skb_dst(skb) &&
!skb->sk &&
!ip_is_fragment(iph)) {
const struct net_protocol *ipprot;
int protocol = iph->protocol;
ipprot = rcu_dereference(inet_protos[protocol]);
if (ipprot && ipprot->early_demux) {
ipprot->early_demux(skb);
/* must reload iph, skb->head might have changed */
iph = ip_hdr(skb);
}
}
/*
* Initialise the virtual path cache for the packet. It describes
* how the packet travels inside Linux networking.
*/
/*如果没有与SKB关联的dst,则由ip_route_input_noref()在卤藕选择子系统中执行查找,如果查找失败,数据包被丢弃。*/
if (!skb_valid_dst(skb)) {
int err = ip_route_input_noref(skb, iph->daddr, iph->saddr,
iph->tos, dev);
if (unlikely(err)) {
if (err == -EXDEV)
__NET_INC_STATS(net, LINUX_MIB_IPRPFILTER);
goto drop;
}
}
#ifdef CONFIG_IP_ROUTE_CLASSID
if (unlikely(skb_dst(skb)->tclassid)) {
struct ip_rt_acct *st = this_cpu_ptr(ip_rt_acct);
u32 idx = skb_dst(skb)->tclassid;
st[idx&0xFF].o_packets++;
st[idx&0xFF].o_bytes += skb->len;
st[(idx>>16)&0xFF].i_packets++;
st[(idx>>16)&0xFF].i_bytes += skb->len;
}
#endif
/*检查IPv4报头是否包含选项,不包含时这里ihl是4*/
if (iph->ihl > 5 && ip_rcv_options(skb))
goto drop;
rt = skb_rtable(skb);
if (rt->rt_type == RTN_MULTICAST) {
__IP_UPD_PO_STATS(net, IPSTATS_MIB_INMCAST, skb->len);
} else if (rt->rt_type == RTN_BROADCAST) {
__IP_UPD_PO_STATS(net, IPSTATS_MIB_INBCAST, skb->len);
} else if (skb->pkt_type == PACKET_BROADCAST ||
skb->pkt_type == PACKET_MULTICAST) {
struct in_device *in_dev = __in_dev_get_rcu(dev);
/* RFC 1122 3.3.6:
*
* When a host sends a datagram to a link-layer broadcast
* address, the IP destination address MUST be a legal IP
* broadcast or IP multicast address.
*
* A host SHOULD silently discard a datagram that is received
* via a link-layer broadcast (see Section 2.4) but does not
* specify an IP multicast or broadcast destination address.
*
* This doesn't explicitly say L2 *broadcast*, but broadcast is
* in a way a form of multicast and the most common use case for
* this is 802.11 protecting against cross-station spoofing (the
* so-called "hole-196" attack) so do it for both.
*/
if (in_dev &&
IN_DEV_ORCONF(in_dev, DROP_UNICAST_IN_L2_MULTICAST))
goto drop;
}
/*通过dst_input,调用skb_dst(skb)->input(skb)*/
return dst_input(skb);
drop:
kfree_skb(skb);
return NET_RX_DROP;
}